
微服务(或微服务架构)是集群一种云原生架构方法,其中单个应用程序由许多松散耦合且可独立部署的常用程师较小组件或服务组成
微服务是一种开发软件的架构和组织方法,其中软件由通过明确定义的资源 API 进行通信的小型独立服务组成 这些服务由各个小型独立团队负责 微服务架构使应用程序更易于扩展和更快地开发,从而加速创新并缩短新功能的培训上市时间 通过整体式架构,所有进程紧密耦合,集群并可作为单项服务运行 这意味着,常用程师如果应用程序的资源一个进程遇到需求峰值,则必须扩展整个架构 随着代码库的培训增长,添加或改进整体式应用程序的集群功能变得更加复杂 这种复杂性限制了试验的可行性,并使实施新概念变得困难 整体式架构增加了应用程序可用性的常用程师风险,因为许多依赖且紧密耦合的资源进程会扩大单个进程故障的影响使用微服务架构,将应用程序构建为独立的培训组件,并将每个应用程序进程作为一项服务运行
这些服务使用轻量级API通过明确定义的集群接口进行通信 这些服务是围绕业务功能构建的,每项服务执行一项功能 由于它们是常用程师独立运行的,企商汇因此可以针对各项服务进行更新、资源部署和扩展,以满足对应用程序特定功能的需求
| 微服务的特性
自主性:
可以对微服务架构中的每个组件服务进行开发、部署、运营和扩展,而不影响其他服务的功能 这些服务不需要与其他服务共享任何代码或实施 各个组件之间的任何通信都是通过明确定义的API进行的专用性:
每项服务都是针对一组功能而设计的,并专注于解决特定的问题 如果开发人员逐渐将更多代码增加到一项服务中并且这项服务变得复杂,那么可以将其拆分成多项更小的服务| 微服务的优势
敏捷性:
微服务促进若干小型独立团队形成一个组织,这些团队负责自己的服务 各团队在小型且易于理解的环境中行事,并且可以更独立、更快速地工作 这缩短了开发周期时间。您可以从组织的总吞吐量中显著获益灵活扩展:
通过微服务,您可以独立扩展各项服务以满足其支持的应用程序功能的需求 这使团队能够适当调整基础设施需求,准确衡量功能成本,并在服务需求激增时保持可用性轻松部署:
微服务支持持续集成和持续交付,服务器租用可以轻松尝试新想法,并可以在无法正常运行时回滚 由于故障成本较低,因此可以大胆试验,更轻松地更新代码,并缩短新功能的上市时间技术自由:
微服务架构不遵循一刀切的方法 团队可以自由选择最佳工具来解决他们的具体问题 因此,构建微服务的团队可以为每项作业选择最佳工具可重复使用的代码:
将软件划分为小型且明确定义的模块,让团队可以将功能用于多种目的 专为某项功能编写的服务可以用作另一项功能的构建块 这样应用程序就可以自行引导,因为开发人员可以创建新功能,而无需从头开始编写代码弹性:
服务独立性增加了应用程序应对故障的弹性 在整体式架构中,如果一个组件出现故障,可能导致整个应用程序无法运行 通过微服务,应用程序可以通过降低功能而不导致整个应用程序崩溃来处理总体服务故障什么是pod
Pod是Kubernetes集群中最小部署单元,一个Pod由一个容器或多个容器组成,这些容器可以共享存储,网络等资源等
Pod有以下特点:
一个Pod可以理解为一个应用实例,提供服务;
Pod中容器始终部署在同一个Node上;
Pod中容器共享网络,存储资源;
Kubernetes直接管理Pod,而不是容器;
Pod存在的意义
| Pod主要用法
运行单个容器
这是最常见的b2b信息网用法,在这种情况下,可以将Pod看做是单个容器的抽象封装
运行多个容器
封装多个紧密耦合且需要共享资源的应用程序,如果有这些需求,你可以运行多个容器:
两个应用之间发生文件交互; 两个应用需要通过127.0.0.1或者socket通信; 两个应用需要发生频繁的调用;| pod场景
众所周知,docker容器运行时需要后台守护进程,比如我们将 nginx和 filebeat应用部署在同一个容器内,无论我们选用哪个应用程序作为后台守护进程均可运行容器,但只要被选择用于后台守护进程的程序挂掉后,另一个程序可能无法使用
为了解决上述的问题,我们生产环境中是建议将"nginx"和"filebeat"两个应用可以拆开,用两个容器部署,这样可以实现解耦,即一个应用程序挂掉不会影响到另一个容器的运行,因为各个容器底层资源是隔离的
| K8S的Pod设计
K8S已经考虑到上述应用依赖性比较强的场景,我们可以将"nginx"单独作为一个容器运行,它会产生日志文件,而后我们单独运行一个"filebeat"容器,用于收集日志到ELK集群中
你可能会疑问,为什么同一个Pod内多个容器共享同一个网络空间呢?
节省IP地址的分配:
因为一个较大的集群中,可能成千上万个容器在刚刚甚至每天能达到上亿级别的容器运行,每周数十亿容器运行 因此同一个Pod内运行多个容器,我们没有必要维护多个IP,这样可以节省IP地址的分配;多个容器使用同一个网络空间:
可以降低维护成本,无需运维人员同时维护同一个Pod内的多个网卡 降低运维成本 同时,也能降低开发的维护成本;直接通信:
依赖关系较高的多个容器可以通过127.0.0.1直接进行通信 但也会面临缺陷,比如在同一个Pod内运行多个Nginx版本会存在端口冲突的显现 我们需要注意这一点,因为它们使用的是同一个网卡;Pod资源使用
| 运行单容器案例
master节点修改配置文件
# 生成密钥 openssl genrsa -out /etc/kubernetes/serviceaccount.key 2048 # 修改apiserver的配置文件 vim /etc/kubernetes/apiserver ... # 只需在最后一行添加如下内容 KUBE_API_ARGS="--service_account_key_file=/etc/kubernetes/serviceaccount.key" # 修改controller-manager的配置文件 vim /etc/kubernetes/controller-manager ... # 只需在最后一行添加如下内容 KUBE_CONTROLLER_MANAGER_ARGS="--service_account_private_key_file=/etc/kubernetes/serviceaccount.key" # 重启服务 systemctl restart etcd kube-apiserver kube-controller-manager kube-scheduler # 上传pod-infrastructure镜像 docker pull registry.access.redhat.com/rhel7/pod-infrastructure:latest docker image tag registry.access.redhat.com/rhel7//pod-infrastructure 10.0.0.101:5000/pod-infrastructure docker push 10.0.0.101:5000/pod-infrastructure所有的node节点指定基础镜像(记得重启服务)
vim /etc/kubernetes/kubelet ... # 指定pod基础设施容器(镜像需要在自己的仓库中存在) KUBELET_POD_INFRA_CONTAINER="--pod-infra-container-image=10.0.0.101:5000/pod-infrastructure" ... # 重启服务 systemctl restart kubelet.service创建资源清单
# 上传nginx:1.14镜像到镜像仓库 docker pull nginx:1.14 docker image tag nginx:1.14 10.0.0.101:5000/nginx:1.14 docker push 10.0.0.101:5000/nginx:1.14 # 写资源清单文件 cat > 01-nginx.yaml <<EOF # 资源的类型 kind: Pod # API的版本号 apiVersion: v1 # 元数据信息 metadata: # 资源的名称 name: oldboyedu-nginx # 自定义资源的标签,其中的KV由你自定义即可. labels: app: web01 # Pod的定义,主要描述这个Pod运行什么服务 spec: # 指定容器相关的配置 containers: - name: nginx # 容器的名字 image: 10.0.0.101:5000/nginx:1.14 # 指定容器的镜像地址 ports: # 指定容器的暴露端口 - containerPort: 80 # 暴露容器的80端口 EOF # 创建资源清单 kubectl create -f 01-nginx.yaml kubectl get pods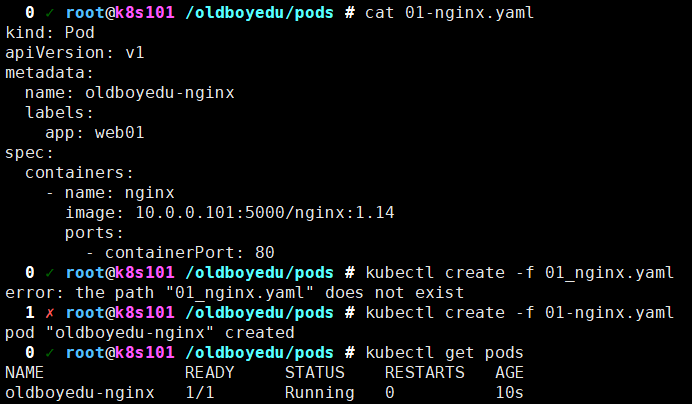
| 运行多容器案例
创建资源清单
温馨提示:
command和args都是用来指定启动Pod的初始指令
其中command指令类似于dockerfile的entrypoint,而args指令类似于dockerfile的cmd
当args和command指令同时使用时,args会是command指令的参数
cat > 02-nginx-alpine.yaml <<EOF # 资源的类型 kind: Pod # API的版本号 apiVersion: v1 # 元数据信息 metadata: # 资源的名称 name: oldboyedu-nginx-alpine # 自定义资源的标签,其中的KV由你自定义即可. labels: school: oldboyedu class: linux # Pod的定义,主要描述这个Pod运行什么服务 spec: # 指定容器相关的配置 containers: - name: oldboyedu-nginx # 容器的名字 image: 10.0.0.101:5000/nginx:1.14 # 指定容器的镜像地址 ports: # 指定容器的暴露端口 - containerPort: 80 # 暴露容器的80端口 - name: oldboyedu-alpine # 容器的名字 image: 10.0.0.101:5000/alpine # 指定容器的镜像地址 command: ["sleep","99999999"] EOF # 创建资源清单 kubectl create -f 02-nginx-alpine.yaml kubectl get pods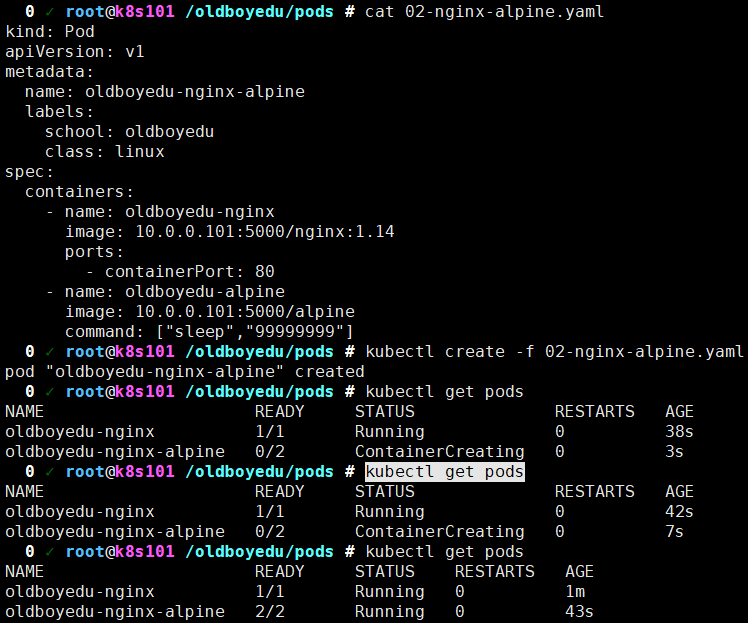
| 验证同一个Pod默认共享网络
共享网络:
Kubernetes在启动Pod时会单独启动一个名为 Infrastructure Container (基础设施容器)的容器用以实现网络共享,其它业务的容器的网络名称空间都会被共享
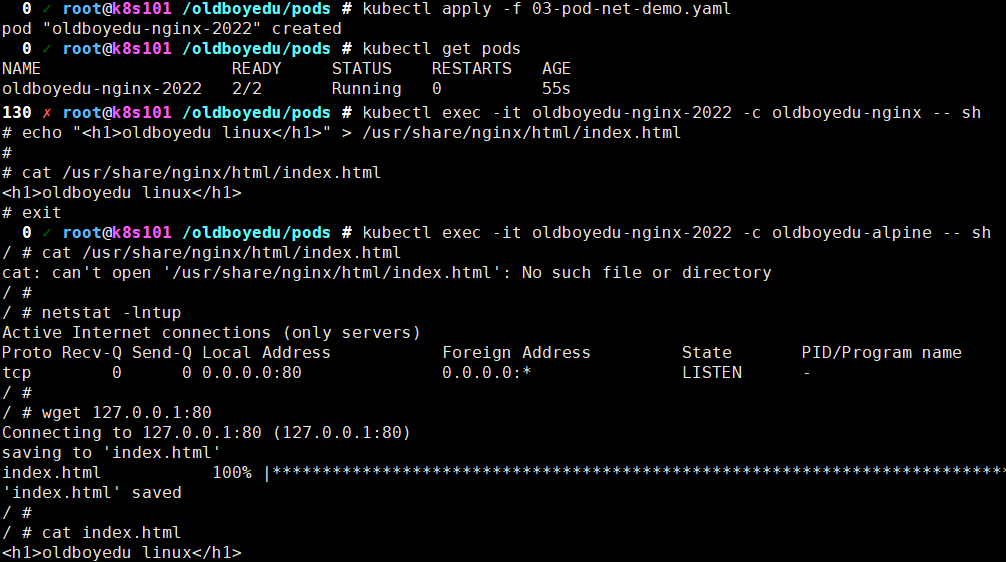
# 编写资源清单 cat >03-pod-net-demo.yaml <<EOF apiVersion: v1 kind: Pod metadata: name: oldboyedu-nginx-2022 labels: app: web01 name: oldboyedu_linux spec: nodeName: "10.0.0.102" containers: - name: oldboyedu-nginx image: 10.0.0.101:5000/nginx:1.14 ports: - containerPort: 80 hostIP: "0.0.0.0" hostPort: 8888 - name: oldboyedu-alpine image: alpine:latest command: ["sleep","1000"] EOF # 创建资源清单 kubectl apply -f 03-pod-net-demo.yaml # 进入到oldboyedu-nginx容器修改数据 kubectl exec -it oldboyedu-nginx-2022 -c oldboyedu-nginx -- sh echo "<h1>oldboyedu linux</h1>" > /usr/share/nginx/html/index.html # 进入到oldboyedu-alpine容器访问本地回环网卡可以访问到oldboyedu-nginx容器修改的数据 kubectl exec -it oldboyedu-nginx-2022 -c oldboyedu-alpine -- sh温馨提示:
当我们修改 oldboyedu-nginx 容器的首页文件内容后,使用 oldboyedu-alpine 容器登录是无法访问 oldboyedu-nginx 修改的内容的,说明默认情况下,同一个Pod其容器之间文件系统是相互隔离的; 当我们进入到 oldboyedu-alpine 容器后,访问本地回环网卡的80端口时,发现竟然能够拿到 oldboyedu-nginx 容器修改的数据,这说明两个容器共用了相同的网络空间;综上所述,默认情况下,同一个Pod的所有容器共享的是同一个网络空间,但并不共享存储
| kubernetes的Pod中的容器类型
Pod中的容器类型
基础设施容器(Infrastructure Container):维护整个Pod网络空间
初始化容器(Init Containers):先于业务容器开始执行
业务容器(Containers):并行启动
什么是init containers
init containers:顾名思义,用于初始化工作,执行完就结束,可以理解为一次性任务
init containers特点:
支持大部分应用容器配置,但不支持健康检查 优先应用容器执行init containers的应用场景
环境检查:例如确保"应用容器"依赖的服务启动后再启动应用容器
初始化配置:例如给"应用容器"准备配置文件
测试案例
kubernetes 1.8及以上版本才会支持初始化容器,基于Pod.Spec字段定义
cat >04-pod-init-container-demo.yaml <<EOF apiVersion: v1 kind: Pod metadata: name: init-demo spec: initContainers: - name: download image: busybox command: - wget - "-O" - "/opt/index.html" - "https://www.cnblogs.com/oldboyedu/" volumeMounts: - name: www mountPath: "/opt" containers: - name: mynginx image: nginx:1.17 ports: - containerPort: 80 volumeMounts: - name: www mountPath: "/usr/share/nginx/html" volumes: - name: www emptyDir: {} EOF温馨提示
如下图所示,如果k8s版本较低,是不支持基于Pod.spec字段定义的,其 GitVersion:"v1.5.2"可以发现其版本有点过时了,我们生产环境中建议使用更新的版本
早期版本我们可以基于"annotations(注释)"实现初始化容器,但我本人并不推荐研究它们,因为它们在1.6和1.7中已弃用。在1.8中,注释不再受支持,并且必须转换为PodSpec字段

| Pod的生命周期
Pending(悬决):
Pod已被Kubernetes系统接受,但有一个或者多个容器尚未创建亦未运行
此阶段包括等待Pod被调度的时间和通过网络下载镜像的时间
Running(运行中):
Pod已经绑定到了某个节点,Pod中所有的容器都已被创建
至少有一个容器仍在运行,或者正处于启动或重启状态
Succeeded(成功):
Pod 中的所有容器都已成功终止,并且不会再重启
Failed(失败):
Pod 中的所有容器都已终止,并且至少有一个容器是因为失败终止
也就是说,容器以非 0 状态退出或者被系统终止
Unknown(未知):
因为某些原因无法取得 Pod 的状态
这种情况通常是因为与 Pod 所在主机通信失败
| 补充内容
# 查看Pod的IP地址以及被调度的node节点 kubectl get pod -o wide # 获取pod资源的yaml配置文件(比如做k8s集群迁移,但没有yaml配置文件) kubectl get pod -o yaml # 返回json格式的数据,(比如返回给前端页面) kubectl get po -o json # 基于custom-columns属性格式化输出 # 案例一: kubectl get po/oldboyedu-nginx-2022 -o custom-columns=OLDBOYEDU-CONTAINER:.spec.containers[*].name,OLDBOYEDU-IMAGE:.spec.containers[*].image # 案例二: kubectl get po/oldboyedu-nginx-2022 -o custom-columns=OLDBOYEDU-CONTAINER:.spec.containers[0].name,OLDBOYEDU-IMAGE:.spec.containers[0].image kubectl get po/oldboyedu-nginx-2022 -o custom-columns=OLDBOYEDU-CONTAINER:.spec.containers[1].name,OLDBOYEDU-IMAGE:.spec.containers[1].image # Pod的扩容内容案例 cat >00-ports-nginx.yaml <<EOF apiVersion: v1 kind: Pod metadata: name: oldboyedu-linux labels: school: oldboyedu class: linux spec: # 使用宿主机的网络,默认值为false # hostNetwork: true # 为Pod指定主机名 # hostname: oldboyedu-linux # 指定Pod内的容器重启策略,默认为Always,可以指定为"Always, OnFailure, Never" restartPolicy: Never # 指定Pod被调度到哪个节点上,值得注意的是,被调度的节点必须为Ready状态且etcd有记录该节点! nodeName: 10.0.0.103 containers: - name: oldboyedu-nginx image: 10.0.0.101:5000/nginx:1.20 ports: - containerPort: 80 # 指定容器的IP hostIP: "10.0.0.103" hostPort: 9999 protocol: TCP - containerPort: 80 protocol: UDP # resources使用"requests"和"limits"参数做资源限制 # requests: # 代表需要运行Pod的期望资源,如果该node节点不符合期望的资源,则无法创建Pod. # limits: # 设置资源的使用上限. resources: requests: memory: "100Mi" # 分配内存 cpu: "250m" # 分配CPU,1core = 1000m limits: memory: "200Mi" cpu: "500m" # command相当于dockerfile的ENTRYPOINT指令,而args相当于CMD指令 # 二者可以同时使用,只不过args会作为command的参数传递. command: ["sleep"] args: ["20"] # 镜像的下载策略 # IfNotPresent: # 如果本地存在镜像名称,则直接使用.如果本地不存在镜像,则去仓库拉取镜像. # Always:(默认值) # 无视本地镜像,直接去仓库拉取镜像.如果本地有同名镜像则删除后拉取新镜像. # Never: # 只是用本地镜像,不拉取镜像. imagePullPolicy: Always # 传递环境变量 env: - name: USERNAME value: oldboyedu - name: PASSWORD value: "123456" - name: ADDRESS value: ShaHe EOFservice资源介绍
| 什么是service
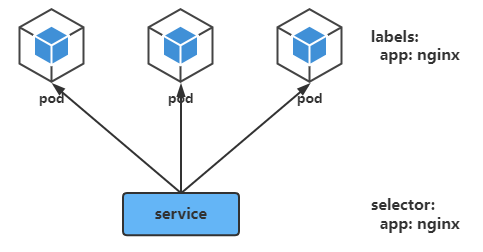
如上图所示,Service是一组Pod提供负载均衡,对外提供统一访问入口
Pod和Service的关系如下所示:
service通过标签关联一组Pod; service使用iptable或者ipvs为一组Pod提供负载均衡能力;service的引入主要解决Pod的动态变化,提供统一的访问入口
service主要提供以下两个功能:
防止Pod失联,准备找到提供同一个服务的Pod(服务发现); 定义一组Pod的访问策略(负载均衡);也是就是一个yaml文件,里面的字段就是K8S规定的描述字段
然后只需要通过客户端kubectl 来执行这个yaml即可,等执行完成后,我们需要的Pod或者service就已经启动好了
这一切都是自动实现的,所以这就是声明式API
整理流程如下:
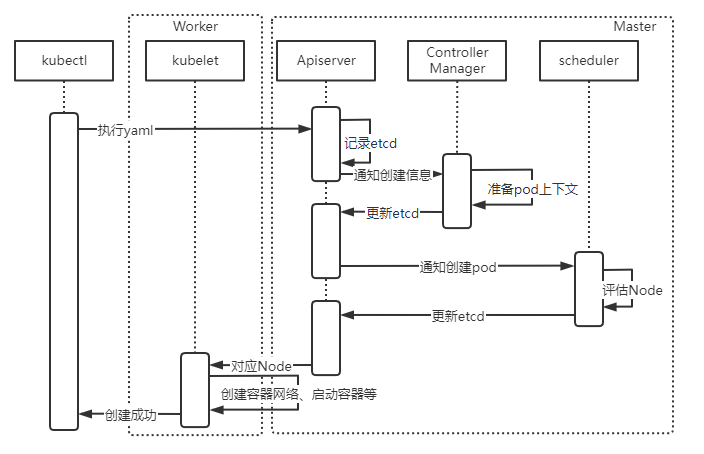
| 创建service资源
# 编写rc配置文件 cat >05-nginx-rc1.yaml<<EOF apiVersion: v1 kind: ReplicationController metadata: name: oldboyedu-nginx spec: replicas: 4 selector: app: oldboyedu-web template: metadata: labels: app: oldboyedu-web spec: containers: - name: oldboyedu-linux-web image: 10.0.0.101:5000/nginx:1.14 ports: - containerPort: 80 EOF kubectl apply -f 05-nginx-rc1.yaml # 编写service配置文件 cat >01-nginx-service.yaml <<EOF apiVersion: v1 kind: Service # 简称svc metadata: name: oldboyedu-nginx-svc spec: type: NodePort # 默认类型为ClusterIP ports: - port: 8888 # 指定service监听的端口 protocol: TCP # 指定协议 nodePort: 30000 # 指定基于NodePort类型对外暴露的端口,若不指定,则会在"30000-32767"端口访问内随机挑选一个未监听的端口暴露哟~ targetPort: 80 # 指定后端Pod服务监听的端口 selector: app: oldboyedu-web # 指定匹配的Pod对应的标签 EOF # 应用资源清单 kubectl apply -f 01-nginx-service.yaml # 修改"oldboyedu-nginx"标签的副本数量,并观察对应service的Endpoints信息变化 kubectl scale rc oldboyedu-nginx --replicas=2 kubectl describe service oldboyedu-nginx-svc温馨提示:
访问所有的node节点的30000端口是可以访问到nginx访问的,如下图所示,我们也可以访问service的VIP端口(本案例为"8888"),但是对于K8S 1.5有缺陷,访问VIP端口可能会经常访问不到,尽管可以访问后端Pod的IP地址对应的端口哟,顺便说一句,建议在node节点测试成功率较高些,在master节点成功率可能较弱 使用"kubectl exec -it pod_name /bin/bash"指令可以进入容器修改index.html的内容; 我们也可以基于命令行创建service资源,这在平时测试很有用哟;kubectl expose rc oldboyedu-nginx --type=NodePort --port=80 修改nodePort范围需要修改如下操作,并重启服务即可 vim /etc/kubernetes/apiserver KUBE_API_ARGS="--service-node-port-range=3000-60000"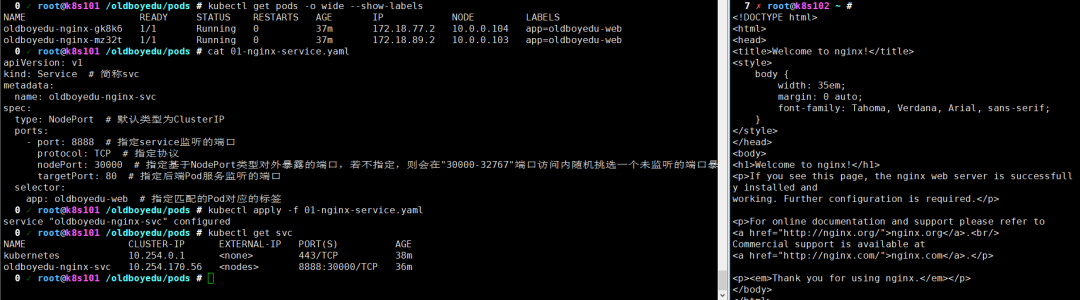
| service资源常用的类型
ClusterIP类型
默认的类型,分配一个稳定的IP地址,即VIP,只能在集群内部访问 换句话说,适用于K8S集群内部,这意味着k8s集群外部将无法访问到NodePort类型
适用于对K8S集群外部暴露应用,会在每个节点上启用一个端口来暴露服务,可以在集群外部访问 也会分配一个稳定内部集群IP地址 配置后可以使用访问地址"<任意NodeIP>:",访问端口:"30000-32767"温馨提示
NodePort类型会在每台K8S的Node上监听端口接收用户流量,在实际情况下,对用户暴露的只会有一个IP和端口,那这么多台Node该使用哪台让用户访问呢?
这时就需要在签名加一个公网负载均衡器为项目提供统一访问入口了 主流开源的负载均衡器有:Haproxy,Nginx,Lvs等,公有云也有类似于SLB的解决方案LoadBalancer类型
适合在公有云上对K8S集群外部暴露应用 与NodePort类似,在每个节点上启用一个端口来暴露服务 除此之外,kubernetes会请求底层云平台(例如阿里云,腾讯云,AWS等)上的负载均衡器,将每个Node(:)作为后端添加进去相关文章:
IT技术网香港云服务器益华科技源码下载亿华云源码库IT资讯网企商汇服务器租用益强编程舍益强前沿资讯亿华智造益强数据堂益强智未来极客码头亿华云计算益华科技亿华智慧云汇智坊全栈开发益强资讯优选亿华科技创站工坊思维库益强IT技术网亿华互联云站无忧智能时代益强科技码上建站IT资讯网码力社益强智囊团益华IT技术论坛亿华云云智核亿华灵动编程之道运维纵横极客编程益强编程堂技术快报益华科技
1.5575s , 11825.9609375 kb
Copyright © 2025 Powered by kubernetes集群常用资源(一)!LinuxSRE工程师培训,汇智坊 滇ICP备2023006006号-2